
https://www.themarketintel...

High-Availability Clustering Software Market Size 2032
High-Availability Clustering Software market size was USD 10.72 billion in 2023 and is projected to touch USD 13.69 billion by 2032, exhibiting a CAGR of 3.1%
https://www.themarketintelligence.com/market-reports/high-availability-clustering-software-market-2771Key Concepts in Machine Learning
Types of Machine Learning:
Supervised Learning: The algorithm is trained on a labeled dataset, meaning that each training example is paired with an output label. Common tasks include classification and regression.
Example: Predicting house prices based on features like size, location, and number of bedrooms.
Unsupervised Learning: The algorithm works on unlabeled data and tries to find hidden patterns or intrinsic structures in the input data. Common tasks include clustering and association.
Example: Grouping customers into different segments based on purchasing behavior.
Semi-supervised Learning: Combines a small amount of labeled data with many unlabeled data during training. It falls between supervised and unsupervised learning.
Reinforcement Learning: The algorithm learns by interacting with an environment, receiving rewards or penalties for actions, and aims to maximize cumulative rewards.
Example: Training a robot to navigate a maze.
[url=https://www.sevenmentor.co... Machine Learning Classes in Pune

Hey everyone,
I am currently setting up high availability (HA) and clustering on a Red Hat Server and want to ensure a stable and efficient configuration. Since downtime can significantly impact business operations, I need a failover mechanism that minimizes service disruptions and ensures continuous availability.
From what I understand, Pacemaker and Corosync are commonly used for clustering in RHEL, but I’d like to confirm the best practices for deployment. When configuring a cluster on a Red Hat Server ( https://www.lenovo.com/de/... ), is a two-node setup sufficient for most workloads, or should I consider a multi-node cluster for added redundancy?
If anyone has experience with high availability on Red Hat Server, I’d love to hear your insights on best configurations, potential challenges.
Thanks in advance.
Jonathan Jone


https://www.debutinfotech....
#AI_Models
#AI_Consulting_Firms
#AI_for_financial_modeling

A Comprehensive Guide to Understanding and Using AI Models
A beginner-friendly guide exploring AI models, their applications, and practical tips for effectively leveraging AI in various industries.
https://www.debutinfotech.com/blog/a-comprehensive-guide-to-understanding-and-using-ai-modelsKey Concepts in Machine Learning
Types of Machine Learning:
Supervised Learning: The algorithm is trained on a labeled dataset, meaning that each training example is paired with an output label. Common tasks include classification and regression.
Example: Predicting house prices based on features like size, location, and number of bedrooms.
Unsupervised Learning: The algorithm works on unlabeled data and tries to find hidden patterns or intrinsic structures in the input data. Common tasks include clustering and association.
url=https://www.sevenmentor.co...
Get an EXTRA 20% OFF your hosting plan!
Hostinger's got a HOT deal! Get an EXTRA 20% OFF your hosting! Don't miss out!

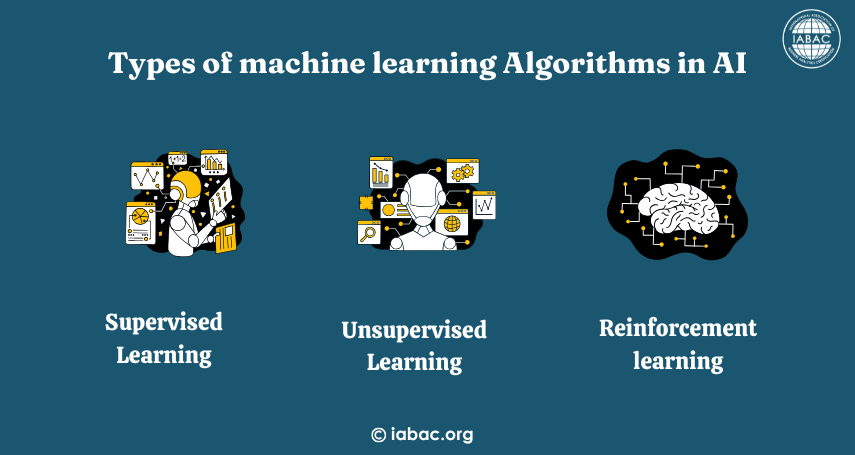
Machine learning algorithms in AI include supervised learning (e.g., linear regression, decision trees), unsupervised learning (e.g., k-means, hierarchical clustering), reinforcement learning (e.g., Q-learning), and semi-supervised learning. Each algorithm addresses specific data analysis tasks or optimization goals.
https://iabac.org/blog/wha...
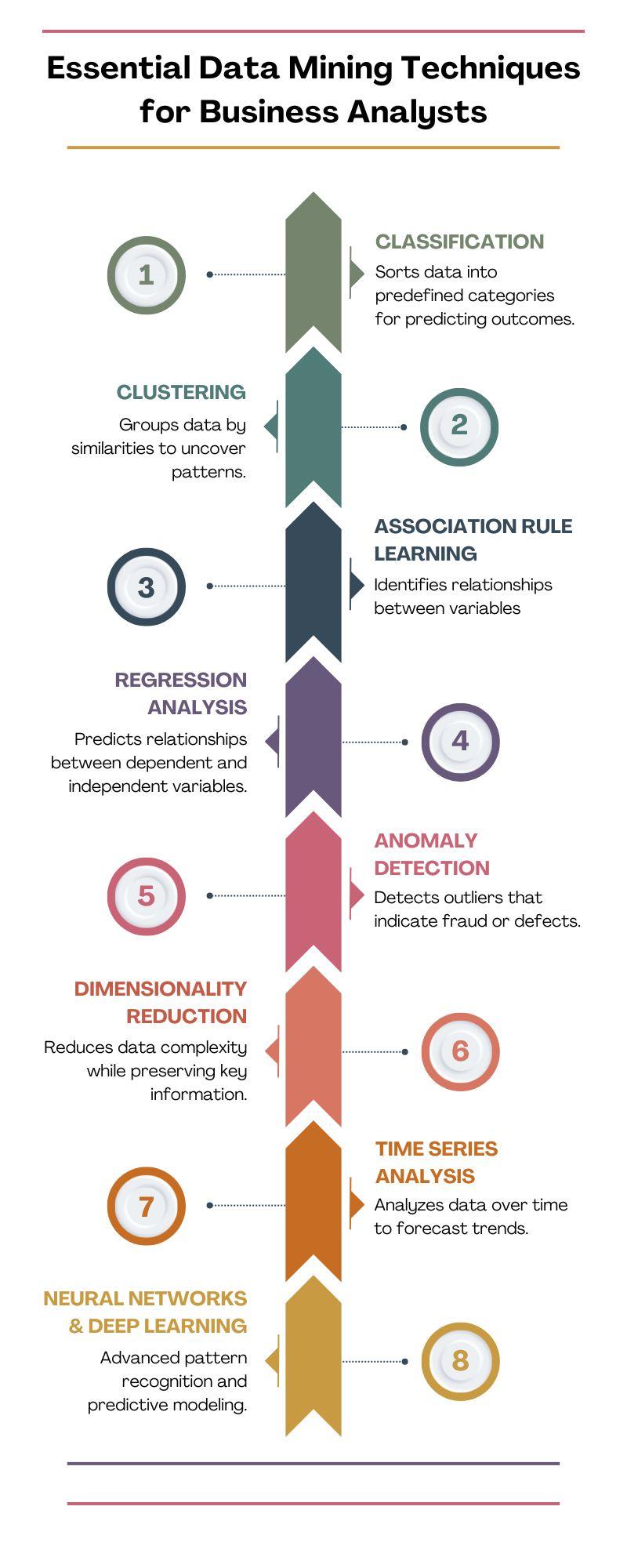
Discover the essential data mining techniques that every business analyst should know. Learn how to extract valuable insights from data using classification, clustering, regression, anomaly detection, and more. Enhance your career with a business analytics course in Hyderabad and unlock the power of data.
Visit: https://skillslash.com/bus...
Market Overview:
During the period 2022-2030, Warehouse Robotics Market is expected to grow to reach USD 13.35 billion by 2030 at a CAGR of 13.5% during the forecast period 2022-2030
The Warehouse Robotics market provides the deployment of robotic technology in the warehouse to perform tasks such as pick-place, material clustering, requesting, stockroom security, examination, transportation, bundling, and palletizing, as well as improve operational efficiency by enormous margins.
"Request Free Sample" - https://www.marketresearch...

Sample Request for Warehouse Robotics Market Size, Share, Global Report 2032
Sample Request - Warehouse Robotics Market Growth is predicted to reach USD 16.6 Billion, at a 13.10% CAGR by driving industry size, share, top company analysis, segments research, trends and forecast report 2024 to 2032
https://www.marketresearchfuture.com/sample_request/5039
Understanding the Essence of Data Mining
Before delving into strategies, let's establish a solid understanding of data mining. At its core, data mining is the process of discovering patterns, trends, and insights from large sets of raw data. It involves various techniques, including clustering, classification, regression, and association rule mining. As you navigate your data mining assignments, keep in mind that each technique serves a unique purpose, and selecting the right one is crucial.
The Power of Help with Data Mining Homework
Embarking on a data mining assignment can be a daunting task, especially when faced with intricate algorithms and complex datasets. This is where seeking help with data mining homework becomes a strategic move. Professional assistance not only provides clarity on challenging concepts but also allows you to grasp the practical application of data mining techniques.
Platforms like https://www.databasehomewo... in providing tailored support for data mining assignments. By leveraging these resources, you gain access to experienced tutors and industry professionals who can guide you through the nuances of your assignment. Collaborating with experts ensures that you not only submit high-quality work but also enhance your understanding of data mining principles.
Strategic Approach to Data Mining Assignments
Now that you recognize the importance of seeking help, let's explore a strategic approach to tackle data mining assignments successfully.
1. Understand the Assignment Prompt Thoroughly
The first step in any successful assignment is a comprehensive understanding of the prompt. Break down the requirements, identify the key concepts, and establish a clear understanding of what is expected. If you encounter any ambiguities, seek clarification from your instructor or utilize the expertise of platforms offering help with data mining homework.
2. Define Your Objectives
Before diving into the technical aspects, define the objectives of your assignment. What insights are you aiming to extract? What patterns or relationships do you expect to discover? Having a clear goal in mind will guide your approach and streamline the data mining process.
3. Choose the Right Data Mining Technique
With your objectives in mind, carefully select the most appropriate data mining technique. Whether it's clustering, classification, or association rule mining, align the technique with your goals. Be prepared to justify your choice, showcasing your understanding of the strengths and weaknesses of each method.
4. Data Preprocessing is Key
Effective data preprocessing is the backbone of successful data mining. Cleanse your dataset, handle missing values, and normalize variables to ensure the accuracy of your results. Paying meticulous attention to data preprocessing sets the stage for more accurate and meaningful analysis.
5. Implement and Validate Your Model
Once you've chosen a data mining technique and preprocessed your data, it's time to implement your model. Be meticulous in your approach, ensuring that your implementation aligns with the chosen technique. Following implementation, validate your model using appropriate evaluation metrics. This step is crucial in demonstrating the effectiveness of your chosen approach.
6. Document Your Process
A well-documented assignment not only showcases your understanding but also facilitates the review process. Document each step of your data mining journey, including data preprocessing, model selection, implementation details, and validation results. Clarity in documentation reflects a systematic approach, earning you additional points in your assignment.
7. Seek Feedback and Iterate
Before finalizing your assignment, seek feedback from peers, instructors, or even the experts providing help with data mining homework. Embrace constructive criticism and iterate on your work. Continuous improvement is a hallmark of success in the dynamic field of data mining.
Conclusion
In the realm of data mining assignments, strategic brilliance is the key to achieving a 90+ success. By understanding the fundamentals, seeking professional assistance, and adopting a systematic approach, you can navigate the complexities of data mining with confidence. Remember, help with data mining homework is not a sign of weakness but a strategic move toward excellence. Embrace the journey, apply these strategies, and watch your academic success in data mining assignments soar to new he

#Datascience #Statistics #MachineLearning #DataAnalysis #InferentialStatistics #DescriptiveStatistics #RegressionAnalysis #ANOVA #BayesianStatistics #TimeSeries #Clustering #KMeans #datavisualization #PredictiveAnalytics #bigdata
https://myvipon.com/post/1...

Top Statistical Methods Every Data Scientist Should Know | Vipon
Save more than 50% with Amazon coupons and promo codes. Get the hottest Amazon products at the lowest price possible.
https://myvipon.com/post/1219068/Top-Statistical-Methods-Every-Data-Scientist-amazon-coupons
Hierarchical clustering and k-means based clustering are two common methods that are used in data analysis as well as machine learning to cluster related data points. Both methods aim to identify clusters in a data set but they differ in the way they approach and the type of clusters they create. This article we’ll examine the differences between hierarchical clustering and K-means clustering in depth. https://www.sevenmentor.co...
Hierarchical Clustering Hierarchical clustering can be described as an approach from the bottom up that is also referred to as agglomerative clumping. It begins by treating each data point as separate cluster. It then joins the most close clusters in a series of iterative steps until a single cluster is left. This process creates a hierarchical structure for clusters, which is often depicted as dendrograms.
Two primary kinds of hierarchical clustering: Agglomerative clustering This starts by treating every data point being an individual cluster, and then gradually merges the clusters closest to it until there is only one cluster left. The merging is dependent on the measure of dissimilarity or similarity between clusters, including Euclidean distance, or correlation coefficients.
Dividesive Clustering The process begins with the entire set of the data points of the same cluster and splits them up into smaller clusters until every data point is located in t

Data mining, the process of extracting patterns and knowledge from large sets of data, has become increasingly crucial in today's data-driven world. From business intelligence to scientific research, data mining plays a pivotal role in uncovering valuable insights. However, navigating the complexities of data mining can pose challenges even to seasoned professionals.
In this blog, we delve into one tough question that often perplexes learners and practitioners alike. But before we dive in, if you're struggling with understanding data mining concepts or need assistance with your assignments, you might wonder, "Where can I find someone to do my data mining homework?" Well, fret not, as resources like https://www.databasehomewo... stand ready to assist you on your data mining journey.
Question: What are the key differences between supervised and unsupervised learning in data mining?
Answer:
Understanding the distinction between supervised and unsupervised learning is fundamental in the realm of data mining.
Supervised Learning:
Supervised learning involves training a model on a labeled dataset, where each input is paired with the corresponding output. The algorithm learns to map inputs to outputs based on this labeled data. This learning process is akin to a teacher supervising a student's learning by providing labeled examples for guidance. In supervised learning, the goal is typically to predict or classify new instances based on past observations. Common algorithms used in supervised learning include linear regression, logistic regression, decision trees, and neural networks.
Unsupervised Learning:
On the other hand, unsupervised learning deals with unlabeled data, where the algorithm must uncover patterns or structures on its own. Unlike supervised learning, there are no correct answers to guide the learning process. Instead, the algorithm explores the data, seeking to identify inherent relationships or groupings. Unsupervised learning can be likened to a student learning independently without direct instruction. Clustering and dimensionality reduction are common tasks in unsupervised learning. K-means clustering, hierarchical clustering, and principal component analysis (PCA) are examples of unsupervised learning algorithms.
#databasehomework #college #University #education #student

https://www.themarketintel...

High-Availability Clustering Software Market Size 2032
High-Availability Clustering Software market size was USD 10.72 billion in 2023 and is projected to touch USD 13.69 billion by 2032, exhibiting a CAGR of 3.1%
https://www.themarketintelligence.com/market-reports/high-availability-clustering-software-market-2771The main differences between deep learning and traditional machine learning lie in the architecture of the models and the feature representation:
Model Complexity:
Traditional Machine Learning: Traditional machine learning models typically involve the manual extraction of relevant features from the input data. Algorithms like decision trees, support vector machines, and k-nearest neighbors work with these handcrafted features.
Deep Learning: Deep learning models, on the other hand, use neural networks with multiple layers (deep neural networks). These models automatically learn hierarchical representations of the data, eliminating the need for explicit feature engineering.
Feature Representation:
Traditional Machine Learning: In traditional machine learning, features are engineered based on domain knowledge or through a trial-and-error process. The performance of the model is highly dependent on the quality of these handcrafted features.
Deep Learning: Deep learning models learn feature hierarchies from raw data. The network automatically discovers relevant features at different levels of abstraction, potentially capturing complex patterns and relationships within the data.
Data Dependency:
Traditional Machine Learning: Traditional machine learning algorithms may require a substantial amount of feature engineering to perform well, and their performance can be limited by the quality and relevance of the chosen features.
Deep Learning: Deep learning models can automatically learn intricate representations from raw data, making them more data-driven and capable of handling high-dimensional inputs without extensive manual feature engineering.
Task Complexity:
Traditional Machine Learning: Traditional machine learning is effective for a wide range of tasks, including classification, regression, clustering, and dimensionality reduction.
Deep Learning: Deep learning excels in tasks that involve large amounts of data and complex patterns, such as image and speech recognition, natural language processing, and tasks where hierarchical feature representations are beneficial.
Training and Computation:
Traditional Machine Learning: Training traditional machine learning models can often be done on standard hardware, and the computational requirements may be relatively modest.
Deep Learning: Training deep neural networks, especially large ones, can be computationally intensive. Graphics Processing Units (GPUs) or specialized hardware are commonly used to accelerate the training process.
Read More...https://bit.ly/3NI3dCT